

Google I/O 2025 was never about subtlety. This year the company left incrementalism and delivered a cascade of generative AI -upgrades aimed at again drawing the card for searches, video and digital creativity.
The Linchpin: Gemini, the next generation of Google, now feeds everything, from search results to video synthesis and image creation with high resolution of new territory in a race that is increasingly defined by how fast and how native, AI can generate.
The showstopper is VEO 3, the first AI videoerer from Google who not only creates visuals, but complete soundtracks – Ambient Ruis, Effects, Even Dialogue – synchronized with the images. Text and image prompts enter and a fully produced 4K video comes out.
This marks the first large-scale video model that can at the same time generate audio and visuals that started with Showrunner Alpha, a non-released model, but VEO3 offers much more versatility, which generates different styles than simple 2D cartoon animations.
“We are entering a new era of creation with combined audio and video generation,” said Google Labs VP Josh Woodward during the launch. It is a direct challenge for the current leaders of the VideoVerven-Kling, Hunyuan, Luma, Wan and OpenAi’s Sora-Veo as an all-in-one solution instead of requiring multiple tools.
In addition to VEO3, imagen 4 – Google’s newest iteration of his image generator model – stops improved photoism, 2k resolution and perhaps even more important, text display that actually works for signposting, products and digital mockups.
For everyone who suffered from the gorgeous text made by earlier AI image models, Image 4 represents a significant improvement.
These tools do not exist separately. Flow AI, a new subscription function for professional users, combines the language options of VEO, Imagen and Gemini in a uniform environment and scene processing. But this integration comes with a price – $ 125 per month to gain access to the full toolkit as part of a promotion period until the full price of $ 250 starts to be charged.

Image: Google
Gemini: search of power power and “text diffusion”
Generative AI is not only for makers of content. Gemini 2.5 now forms the backbone of the redesigned search engine of the company, which wants to evolve Google from a link-aggregator to a dynamic, conversation interface that handles complex searches and supplies synthesized, multi-source answers.
AI overviews – where Google Gemini tries to give extensive answers to questions without users having to click on other sites – is now at the top of search pages, where Google reports more than 1.5 billion monthly users.
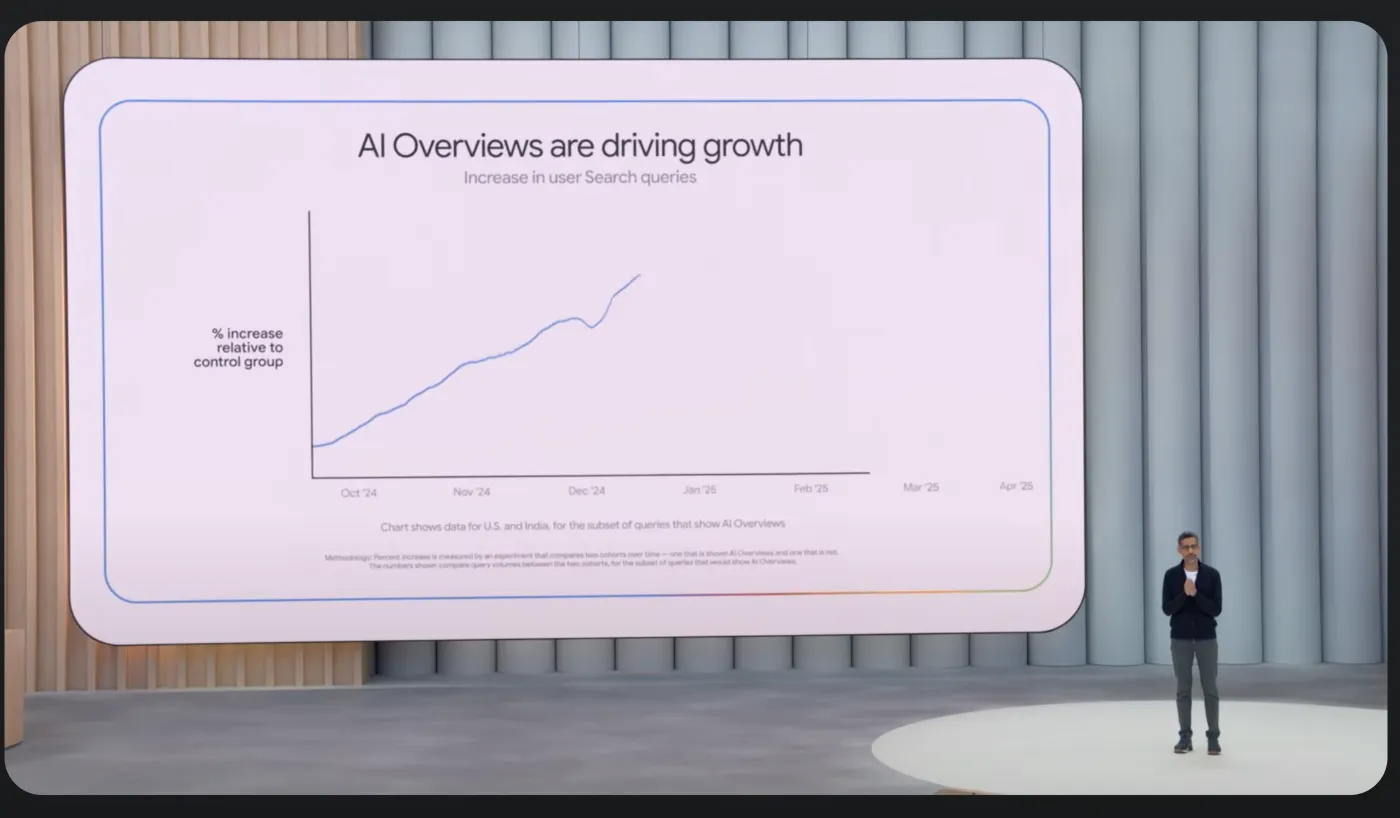
Image: Google via YouTube
Another interesting development is “Gemini Diffusion”, built with technology developed by Inception Labs months ago. Until recently, the AI community generally agreed that auto -bright technology worked best for generating text, while the diffusion technology excelled for images.
Auto -bright models generate each new token after reading all previous generations to determine the best following token – ideal for making coherent text reactions by constantly viewing the fast and earlier output.
Diffusion technology works differently, starting with filling all context with random information and refining (distributing) the export each step to allow the end product to match the prompt – perfect for images with fixed cloths and aesthetics.
OpenAi first successfully applied AutoRegressive Generation to image models, and now Google has become the first major company that applied diffusion rotation to text. This means that the model starts with nonsense and the entire output refines with each iteration, produces thousands of tokens per second while retaining the accuracy – for context, grok (not Xai’s grock), which is one of the fastest inference suppliers in the world, cannot get close to those speeds.
However, the model is not yet publicly available – interviewed users must participate in a waiting list – but early adopters have shared impressive results that show the speed and precision of the model.
Google Gemini diffusion is crazy
The hand of 2SEC responses is a breathing
you have to try it
Real -time video: pic.twitter.com/f06cosxv2v
– Kickiniteasy (@kickiniteasy) 21 May 2025
Hands-on with the AI tools of Google
We have received several new AI functions from Google, with mixed results, depending on the layer.
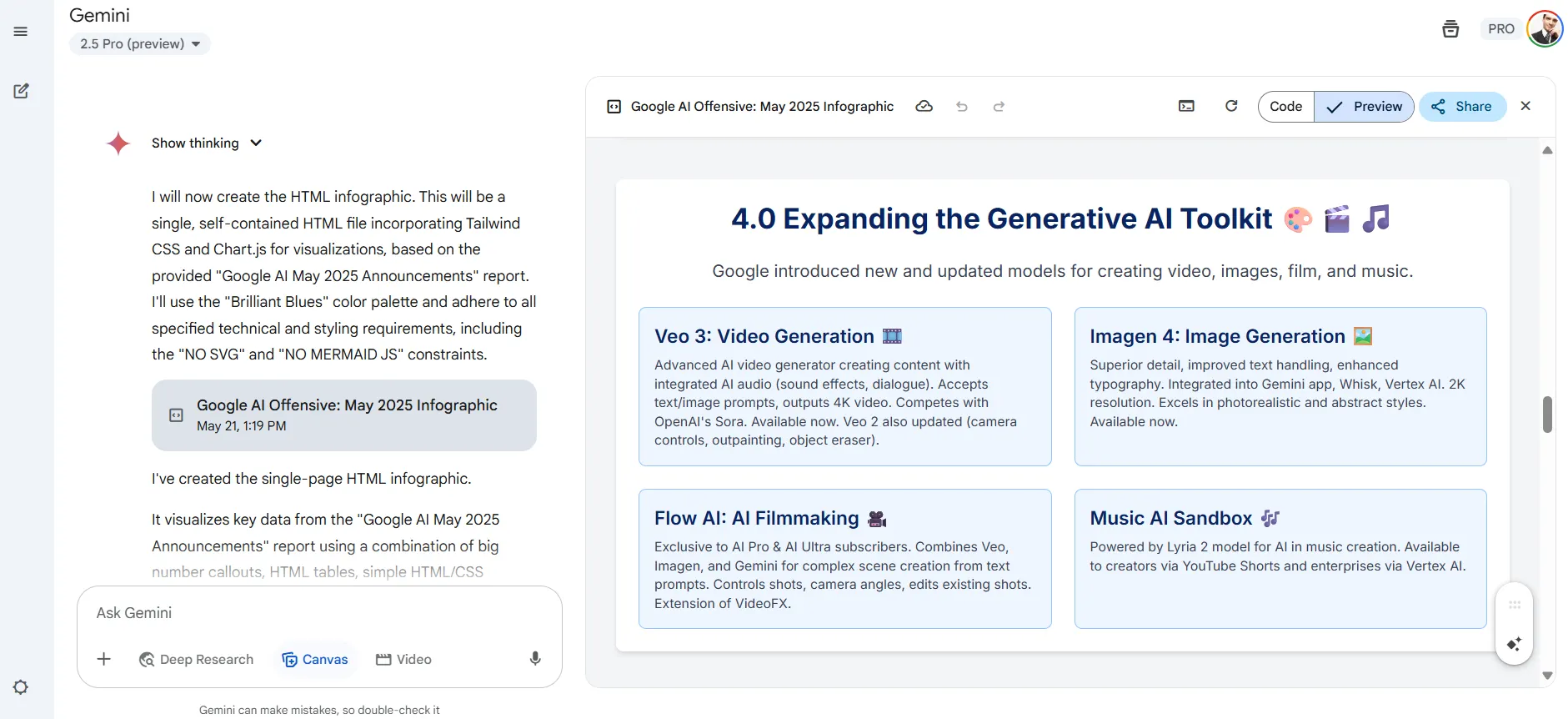
Deep research is particularly powerful – even beating chatgpt alternative. This extensive research agent evaluates hundreds of sources and provides reliable information with minimal errors.
What gives it a lead on the OpenAI research agent is the possibility to generate infographics. After producing a full research text, it can condense that information in visually attractive slides. We fed the model everything about the latest announcement from Google and it presented accurate information through graphs, schedules, graphs and mind cards.
VEO 3 remains exclusively for Gemini Ultra users, although some external providers such as Freepik and Fal.ai already offer access via API. Flow is not available to try unless you jump in front of the ultraplan.
Flow appears to be an intuitive video editor with Veo’s models in the core, allowing users to edit, cut, expand and change AI scenes with the help of simple text prompts.
Even Veo2, however, got a little love, which makes life easier for professional users. Generations with the now accessible VEO2 are considerably faster-We have made 8 seconds video in about 30 seconds. Although VEO2 Sound fog and currently only supports text-to-video (with image-to-video soon), it understood our prompts and even generated coherent text.
VEO2 is already performing comparable to Kling 2.0 – considered the quality benchmark in the generative video industry. The new generations with VEO3 seem even more realistic, more coherent, with a good background noise and lifelike dialogue and voices.
Really not. It did it. And was that actually funny?
Fast:
> A man who puts a stand -up comedy in a small location tells a joke (take the joke in the dialogue) https://t.co/gfvpassehx pic.twitter.com/lrcivap1bl– FOFR (@fofrai) May 20, 2025
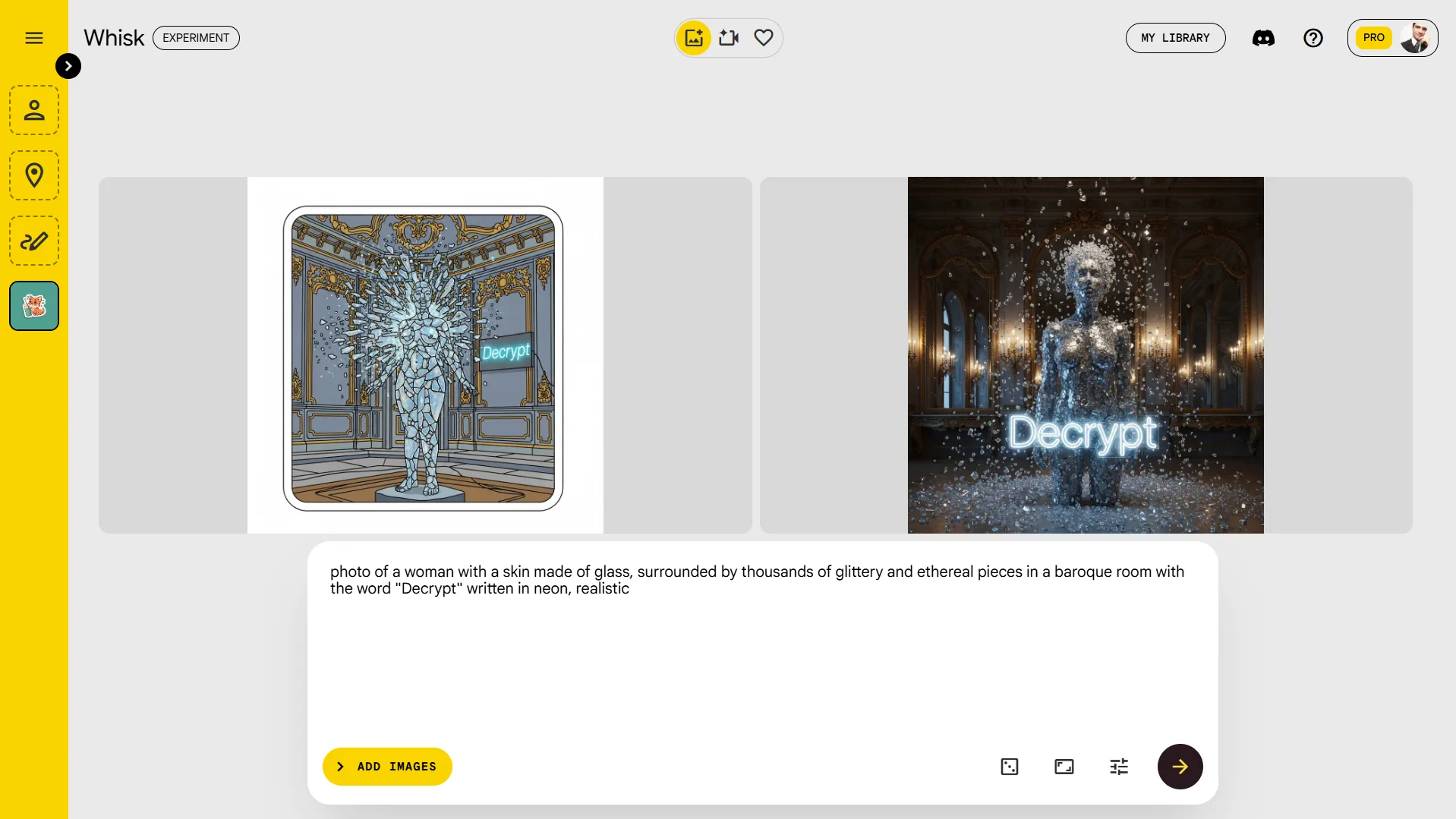
For Imagen it is difficult to determine at first glance whether Google version 4 records or still uses version 3 on the Gemini Chatbot interface, although users can confirm this via a whisk. Our first tests suggest that Image 4 priority gives realism, unless otherwise specified, with better fast compliance and visuals that surpass his predecessor.
We have generated an image with different elements that usually do not fit together in the same scene. Our prompt was “photo of a woman with a skin made of glass, surrounded by thousands of glitter and essential pieces in a baroque room with the word” Decodeer “written in neon, realistic.”
Although both imagen 3 and imagen 4 understood the concept and the elements, Image 3 did not succeed in capturing the realistic style – which imagen 4 did easily. In general, Image 4 is similar to the Sota image generators, especially considering how easy it is to ask.
Audio overviews have also been improved, with models that now easily offer more than 20 minutes of full debates about Gemini instead of forcing users to switch to NotebookLM. This makes Gemini a more complete interface, reducing the fragmentation that previously required users to jump between different sites for different services.
The quality is comparable to that of Notebooklm, with on average slightly longer outputs. However, the most important characteristic is that the model is better, but that it is now embedded in Gemini’s Chatbot user interface.
Premium AI at a premium price
Google has not hidden the strategy for generating income. The “Ultra” plan of the company costs $ 250 monthly, bundling of priority access to the most powerful models, flow AI tools and 30 terabytes of storage -aimed at filmmakers, serious makers and companies. The $ 20 “AI Pro” tier unlocks Google’s previous VEO2 model, together with image and productivity functions for a wider user stock. Basic generative tools – such as simple Gemini live and image creation – leave free, but with limitations such as a token hood and only 10 studies per month.
This layered approach reflects the wider AI market trend: Drive Massa -acceptance with Freebies and then lock the professionals with functions that are too useful to leave. Google’s bet is that the real action (and margin) high-end creative work and automated Enterprise Workflows are not only casual instructions and meme generation.
Published by Andrew Hayward