

The crawlers from Pertlexity remained access to the content of tens of thousands of websites, even after those sites had explicitly blocked them, according to Cloudflare of internet infrastructure provider. The company said on Monday that the astonishment had removed from his verified Bot program and blocks implemented against what it was characterized as misleading scrap practices.
The perplexity established in San Francisco was founded in 2022 by Aravind Srinivas (CEO, former OpenAI researcher), Denis Yarats (former Facebook AI), Johnny Ho and Andy Konwinski (co-founders of Databricks). The company has received financing from investors, including Elad Gil, Nat Friedman (former Github CEO) and Nvidia, among other things and was appreciated at $ 18 billion after collecting $ 100 million last month.
The recent conflict broke out after Cloudflare customers still complained that Perplexity still scraped their sites, despite the implementation of both robots. TXT guidelines and specific firewall rules to block the explained crawlers of the AI company. CloudFlareers Gabriel CORAL, VAIBHAV Singhal, Brian Mitchell and Reid Tatoris confirmed in tests that “PerTlexity’s crawlers were in fact blocked on the specific pages in question.”
To test the behavior of Perplexity, Cloudflare created several newly purchased domains with restrictive robots.txt files that prohibit all automated access. “We have carried out an experiment by questioning perplexity AI with questions about these domains, and discovered that perplexity still provided detailed information about the exact content hosted on each of these limited domains.”
What happened afterwards surprised them. Instead of respecting the blocks, changing tactics seemed to change. “We have noted that Pertlexity not only uses their explained user agent, but also a generic browser that was intended to submit Google Chrome to macOS when their explained Crawler was blocked,” the engineers wrote.
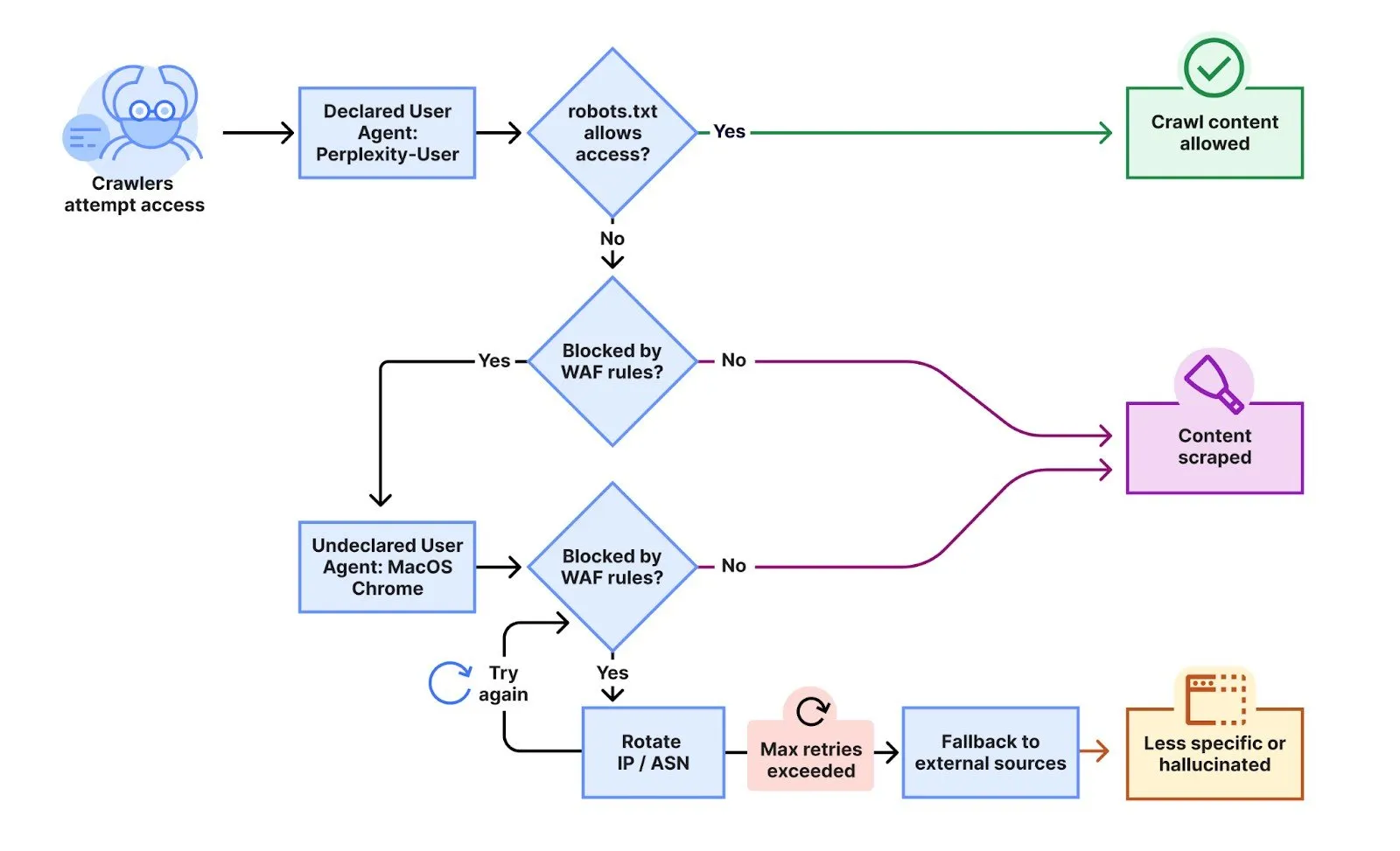
The Stealth Crawlers used advanced evasion techniques. “This non -given crawler used several IPs that were not mentioned in the official IP range of Perflexity and would rotate through these IPs in response to the restrictive robots. TXT policy and blocking cloudflare. In addition to rotating IPs, we have observed requests that came from different ASNs to further altogens.”
According to CloudFlare, the “explained” crawlers of Perplexity-Degenants who are easily identifiable generally generate 20-25 million requests, while the non-declared stealth-crawlers that are dependent on shady tactics to hide their goal. “This activity was observed in tens of thousands of domains and millions of requests a day.”
The company did not respond to DecryptThe request for comments. A spokesperson has rejected the allegations Techcrunch If nothing more than a “sales talk” in Cloudflare.
Matthew Prince, CEO of Cloudflare, has been pronounced about what he sees as the non -durable extraction of web content of AI companies. “Looking for traffic references are plummeted as people who are increasingly trusting AI entitlements.” In July he unveiled devastating ratios: while Google sends one visitor for every 18 pages it crawls, AI companies are much worse. The ratio of OpenAi deteriorated today from 250-to-1 to 1500 to 1 today. Anthropic figures are even more extreme and jump from 6,000 to 1 to 60,000 to 1 in the same period.

Source: Cloudflare
This led to Cloudflare to start what the “content Independence Day” calls, in default to block AI-Crawlers for all new domains, and became the de-Facto Burgerwacht that protect the makers of content against the threats of annoying AI-Crawlers.
When Decrypt Previously reported, more than a million websites had chosen since last fall to block, with large publishers, including the Associated Press” Time” The Atlantic Ocean” BuzzfeedReddit, Quora and Universal Music Group Member of the Movement.
“There are clear preferences that Crawlers must be transparent, serve a clear goal, carry out a specific activity and, more importantly, follow website guidelines and preferences,” Cloudflare stated. The company contrasted Pertlexity’s behavior with OpenAI, which it said that it respects robots in the right way. TXT files and stops crawling when blocked.
Cloudflare’s response includes both immediate technical measures and in the longer term initiatives. The company has used characteristic competitions for the Stealth Crawler in its managed rules, available for all customers, including free users. It also develops tools such as an “AI Labyrinth”, which non-compliant bots of brokers of fake content, and a “pay-per-crawl” market, with which publishers can charge AI companies for access to their content.